Spark Installation:
Spark is one of the frame-work, in-memory data processing engine. It is 100 times faster than Hadoop MapReduce for data processing. Spark is developed by SCALA, JAVA, Python programming languages for Hadoop & Spark developers in Big Data and Analytics.
Here is Apache Spark Installation Prerequisites:
1. Update the Packages on Ubuntu/Linux operating system
sudo apt-get update
2. Install Java 1.7 or more version using below command:
sudo apt-get install default -jdk
Complete Installation of Spark on Ubuntu 16.04 steps with pictures:
Step 1: Download the Spark tarball from Apache Spark mirror official website.
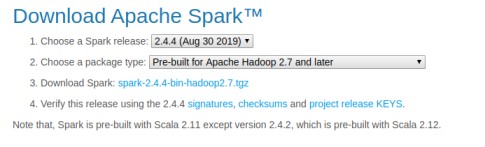
A. Here choose a Spark Release which version we want
B. After that choose package type which version we want from the dropdown button
C. After selecting the Spark version click on Download Spark
the latest version for more features.
Step 2: Extract the Spark latest version tarball by directly right click on that tarball otherwise will use the command on terminal :
tar -xzvf spark-2.4.4-bin-hadoop2.7.tar.gz
Please find below a snapshot for more information:

Step 3: After tarball extraction, update the Spark home and path variables in bashrc file on the home directory.
.bashrc file – > Ctrl+H on Home directory will see .bashrc file then open that file and edit below like otherwise use the terminal command “~/.bashrc”
export SPARK_HOME = /home/sreekanth/Spark/spark_version export PATH=$PATH:$SPARK_HOME/bin
![]()
Step 4: How to check the Spark home and path exists or not.
A. Open a new terminal and use below command:
echo $SPARK_HOME
Note: Don’t use the previous terminal.
Step 5: After completion of the above steps successful installation of Spark on Ubuntu 16.04
Step 6: Then open Spark shell on the terminal by using the below command:
spark-shell
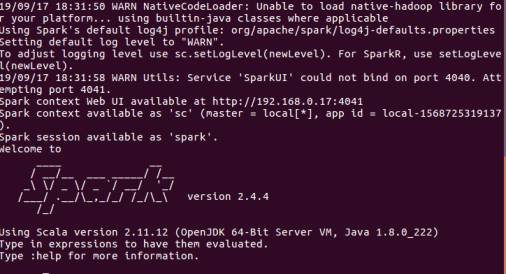
After open Spark shell will be showing like the above screenshot. It showing Spark version with Java version also.
Summary: In Big Data & Analytics, Hadoop is one of the solutions to provide storage and processing. While processing data MapReduce is one of the solutions. But once Spark is coming to picture, MapReduce is going down due to Spark is light and 100 times faster than MapReduce for large data processing. The above simple steps to the installation of Spark on Ubuntu 16.04 version with pictures.