In Spark groupByKey, and reduceByKey methods. Here is we discuss major difference between groupByKey and reduceByKey
What is groupByKey?
- The groupByKey is a method it returns an RDD of pairs in the Spark. Where the first element in a pair is a key from the source RDD and the second element is a collection of all the values that have the same key in the Scala programming. It is basically a group of your dataset based on a key only.
The groupByKey is similar to the groupBy method but the major difference is groupBy is a higher-order method that takes as input a function that returns a key for each element in the source RDD. - The groupByKey method operates on an RDD of key-value pairs, so key a key generator function is not required as input.
Example:
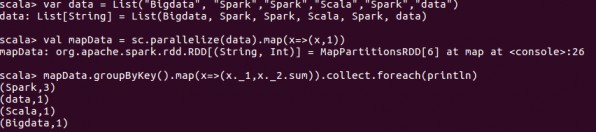
groupByKey
Scala > var data = List ("Big data","Spark","Spark","Scala","","Spark","data")
Scala > val mapData = sc.parallelize(data).map(x=>(x,1))
Scala > mapData.groupByKey().map(x=>x._1,x._2.sum)).collect.foreach(println)
Output:
(Spark,3)
(Data,1)
(Scala,1)
(Bigdata,1)
What is reduceByKey?
- The reduceByKey is a higher-order method that takes associative binary operator as input and reduces values with the same key. This function merges the values of each key using the reduceByKey method in Spark.
- Basically a binary operator takes two values as input and returns a single output. An associative operator returns the same result regardless of the grouping of the operands. It can be used for Calculating sum, product, and Calculating minimum, or a maximum of all the values mapped to the same key.
Example:
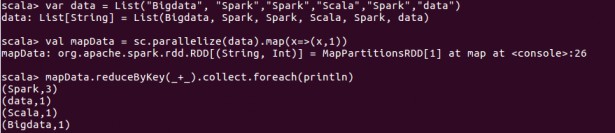
reduceByKey:
Scala > var data = List ("Big data","Spark","Spark","Scala","","Spark","data")
Scala > val mapData = sc.parallelize(data).map(x=>(x,1))
Scala > mapData.reduceBykey(_+_).collect.foreach(println)
Ouput:
(Spark, 3)
(data ,1)
(Scala ,1 )
(Bigdata, 1)
groupByKey vs reduceByKey
The above two transformations are groupByKey and reduceByKey, we are getting the same output.
So we avoid “groupByKey” where ever possibly follow the below reasons:
- reduceByKey works faster on a larger dataset (Cluster) because Spark knows about the combined output with a common key on each partition before shuffling the data in the transformation RDD.
- When we calling the groupByKey method then take all the key-value pairs are shuffled around. This is a lot of useless data to being transferred over the network.