Why Hadoop 1.x failure?
In Hadoop 1.x, NameNode was a single point of failure. NameNode failure makes the Hadoop cluster inaccessible. In this version, Hadoop Admin has more manually worked on the Namendoe using Secondary NameNode.
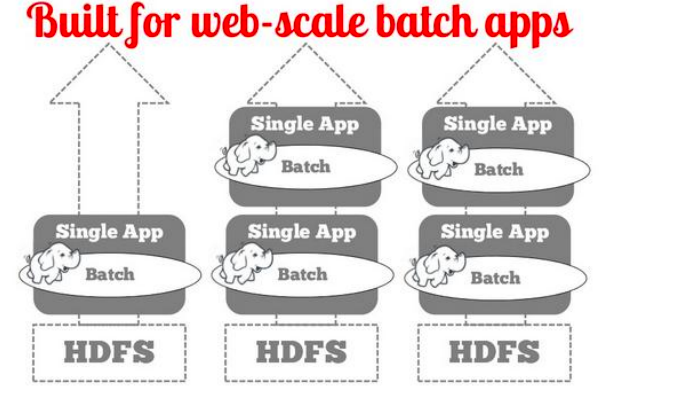
Hadoop 1 is a built for web-scale batch apps for Single application into HDFS
What is Hadoop 2?
Basically, Hadoop 2 is the second version of the Apache Hadoop framework for storage and large data processing. It supports for running non-batch applications through YARN, and cluster redesigned with the resource manager. After Hadoop 1.x version Apache includes new features to improve systems like Availablity and scalability
Built for web-scale batch applications in Hadoop Distributed File System (HDFS)
Why Hadoop 2 overcomes Hadoop 1.x?
Below four improvements in Hadoop 2.x version over Hadoop 1.x
- Hadoop Distributed File System Federation (HDFS F): Horizontal scalability of Name Node in Hadoop Cluster
- Yet Another Resource Neogotiaite (YARN): It is the ability to process TB and PB of data available in the Hadoop Distributed File System.
- Name Node HA: Name Node High availability is no longer a single point fo failure
- RM: Resource Manager is split up into two functionalities. One is Job Tracker and another one is NodeManger ( Application Master + Task Tracker)
MapReduce is good for below-built points:
- Parallel algorithms – Some of the Bit-level algorithms
- Summing, grouping, filtering, joining operations
- Offline batch jobs on large file data including video-related data
- Analyzing an entire large data sets with a proper file system
MapReduce is OK for below bullet points:
- Iterative jobs like algorithms including datastore point of view
- Each iteration must read/write data for users in the Hadoop cluster
- I/O (Input/Output) and computing cost of an iteration is high
MapReduce is not good for the below points:
- MapReduce Jobs that need to be shared state/coordination
- The shared state requires scalable state store
- Low computing jobs in the Hadoop cluster
- Jobs on small datasets
- Finding discrete records
MapReduce Limitations:
Scalability:
- Maximum cluster size around 4,500 nodes within the Hadoop cluster
- Maximum concurrent task 40K in Hadoop 2.x
Availability:
- Failure kills all queued and running jobs
Lacks support for alternate paradigms and services:
- Iterative applications implemented using MapReduce are 10X slower
- Hard partitions of resources into map and reduce slots
- Low resource utilization in the MapReduce.