Spark is an in-memory framework for huge data processing in the BigData environment. Here is creating the first Spark application in IntelliJ IDEA with Sbt.
Prerequisites:
- IntelliJ IDEA
- Scala
- Basic knowledge of Spark
Create First Spark Application in IntelliJ IDEA with SBT
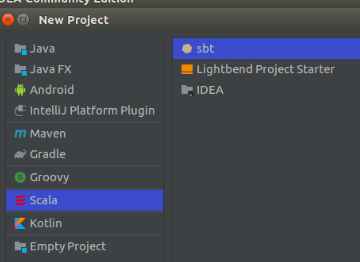
Step 1: Open IntelliJ IDEA, select “New Project”. After that choose Scala with Sbt then click on the “Next” button.
Step 2: Provide your Project Name and Location of your programs. Here we selected JDK 1.8 version, Sbt: 1.1.6 version, and the select Scala version 2.11.12. I followed the above versions if you want new versions then select it. Then click on the “Finish” button.
Step3: After clicking on the “Finish” button it will take some time for sync up with Sbt structure.
Step 4: Will get the Spark Application structure with below hierarchy:
Spark Application-> Project -> .idea -> src -> main->packages -> App -> test -> target -> build.sbt External Libraries
Here we created “New Project Name: Spark Application”. Default we get main and test subfolders within the source folders. In the main subfolder, we created the package and created an application with “Scala Object”. Please check with the snapshot.

Step 5: Next go to Maven repository for Spark Core dependencies. Copy the “SBT” code in the Maven page to build.sbt file in IDE like the below screenshot. It will take some amount of time for Spark Core dependencies from Maven repositories.
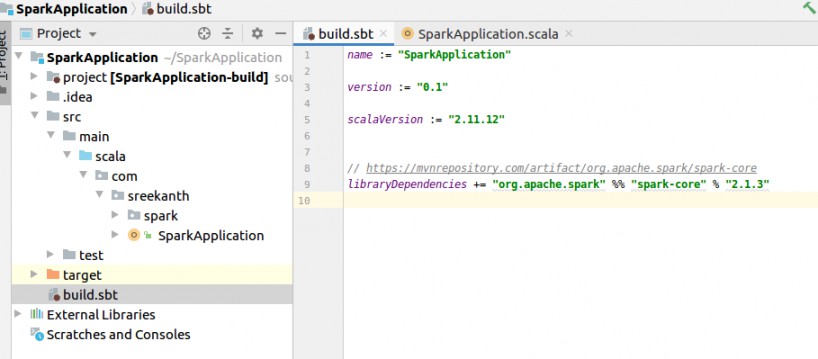
Note: In Maven repository please select “SBT” only then will get Sbt code.
Step 6:Next go to SparkApplication and write simple code with import, packages with Spark RDDs for our understanding.
package com.sreekanth
import org.apache.spark.{SparkConf, SparkContext}
object SparkApplication {
def main(args:Array[String]): Unit = {
val conf =new SparkConf()
conf.setMaster("local")
conf.setAppName("First Spark Application")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(Array(100,200,400,250))
rdd1.collect().foreach(println)
}
}
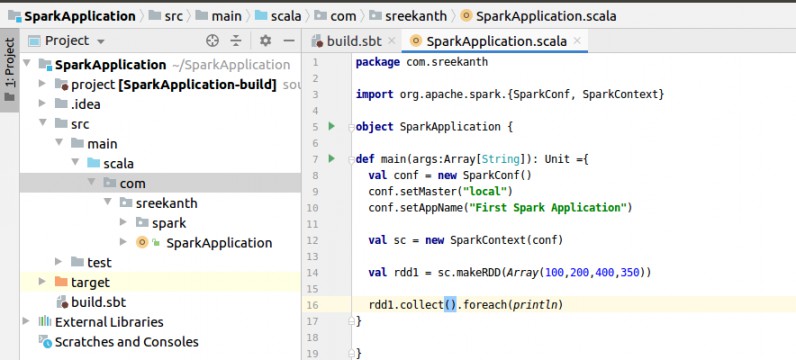
In the above Spark Application program created a Spark Config and Spark Context to initialization of Spark. And created makeRDD for Array.
Step 7: Right-click on the Spark Application “Run Spark Application”. Then we will get the output in the console like below:

Summary: For Data Engineers Spark is a mandatory skill for large data processing. Beginners need to how to execute the first Spark application in IntelliJ IDEA with SBT. Here is how to create Scala Object, and import Spark dependencies from Maven official website. After that Run the application.