HBASE – Hadoop dataBASE
Apache HBase runs on top of Hadoop. It is a Database which is an open source, distributed, NoSQL database related.
Hadoop can perform on batch processing and data will access only in sequential manner leading with low latency but HBASE internally uses Hash tables and provices random access, and stores the data in HDFS files that are indexed by their key for faster lookups thus providing high latency comapred to Hadoop HDFS.
Here Comparison HBASE and RDBMS
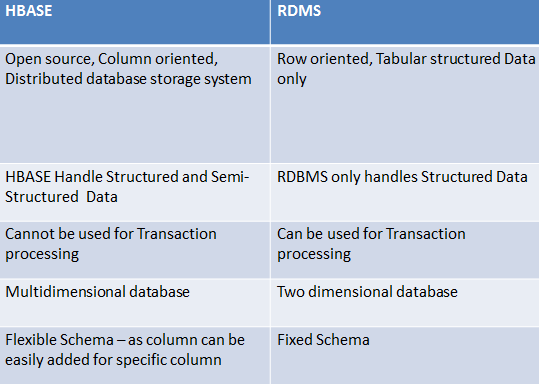
Some more points for comparison of HBASE and RDBMS :
HBASE doesnot directly supports JOINS or Aggregations and it can handle large amount of gdata
RDMSB supports JOINS, Aggregations using SQL and it can handle limited amount of data at a time.
The comparison of HBASE and HDFS :

HBase is a distributed, column oriented database and stores data in key,value pairs. In HDFS is a distributed file system and stores data in the form of flat files.
HBase random reads and writes but HDFS sequential file access random writes are not possible as it allows to write once and read many times.
HBase is a suitable for Low latency operations by providing access to the specific row data from the big volume. In HDFS suitable for High Latency operations through batch processing.
The comparison of HBASE and NoSQL:

HBase is a NoSQL database, data stores in <key,value> pair. In NoSQL by default, Value is stored in key, value pair.
HBase is a Horizontal scalability, No SQL also Horizontal Scalability.
HBase uses MapReduce for processing data but in NoSQL can perform basic CRUD operations. Complex aggregations are tough to handle so we need to integrate with solutions like Hadoop for complex processing.
HBase Maste Slave model to address parallel processing
HBase may permit two types of access: random access of rows through their row keys and offline or batch access through map-reduce queries. In NoSQL Random access of data is possible