Hive Query error while executing in the Hadoop cluster:
Below snapshot is belongs to Hive HQL script query error in the Hadoop cluster environment.
I try to write a Hive query in Hive CLI in the Hadoop cluster environment after that executing query getting below error:
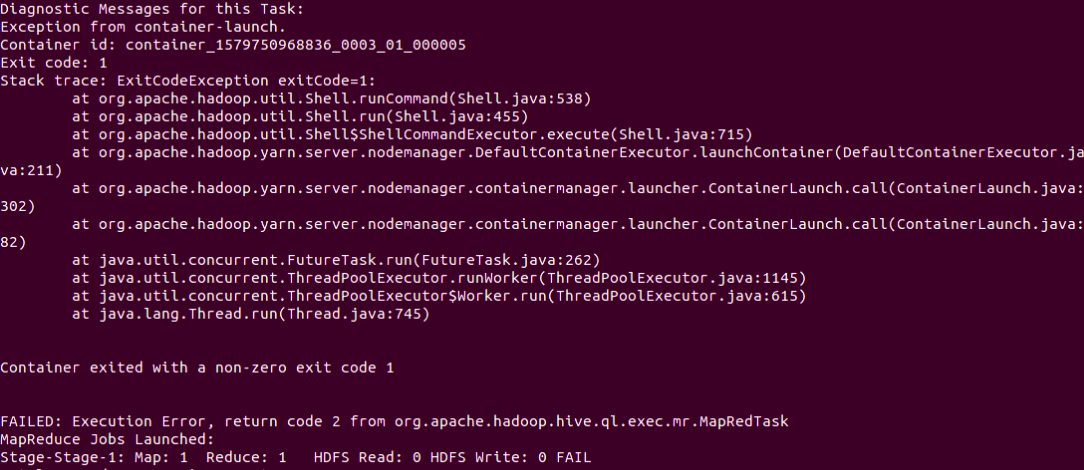
Diagnostic Messages for this Task: Exception from the container - launch Container id: container_ Exit code: 1 Stack trace: ExitCodeException exit code = 1: at org.apache.hadoop.util.Shell.runCommand(Shell.java:538) at org.apache.hadoop.util.Shell.run(Shell.java:455) at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715) at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:211) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.ThreadPoolExecutor.runWorker(threadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745) Container exited with a non zero exit code 1 Failed: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask MapReduce Jobs Launched:
Resolution:
First check with yarn log file based on your’s application id using below command in the edge node server:
yarn logs application - applicationId <applicationId>
Otherwise, directly go with the resource manager then check the full log file.
If you find above the same error then take the input file put into HDFS path location after the execute query then definitely it will execute correctly.
Summary: The above error belongs to the input file path issue. I put the input file in the Local File system (LFS). After that file put into Hadoop Distributed File System(HDFS) then execute Hive HQL script then it’s executed correctly with an exact solution in the Hadoop cluster environment. In a Bigdata distribution like Clouder, Hortonworks, MapR distributions put the file directly into the HDFS path. In Cloudera goto HUE then open HIVE CLI prompt then try to execute the Hive HQL script simply. Coming to MapR distribution go to Hive CLI then execute the HQL scripts will get output exactly. First, try to check your classpath and provide the full and exact path to yarn in the HDFS. The yarn server(resource manager) node manager will be showing everything about this error in the Hadoop cluster environment.